NS-Gym#
NS-Gym (Non-Stationary Gym) is a flexible framework providing a standardized abstraction for both modeling non-stationary Markov Decision processes (NS-MDPs) and the key problem types that a decision-making entity may encounter in such environments. NS-Gym is built on top of the popular Gymnasium library and provides a set of wrappers for several existing environments, making it easy to incorporate non-stationary dynamics and manage the nature of agent-environment interaction specific to NS-MDPs. A key feature of NS-Gym is emulating the key problem types of decision-making in non-stationary settings; these problem types concern not only the ability to adapt to changes in the environment but also the ability to detect and characterize these changes. To get started with NS-Gym, check out our Installation instructions and Quickstart Guide. For a deep dive into the core concepts behind NS-Gym, visit our Core Concepts page or take a look at our paper on ArXiv published at NeurIPS 2025 Dataset and Benchmarks track.
Paper#
Please take a look at our paper accepted to the NeurIPS 2025 Dataset and Benchmarks Track for more details on NS-Gym:
@inproceedings{
keplinger2025nsgym,
title={{NS}-Gym: A Comprehensive and Open-Source Simulation Framework for Non-Stationary Markov Decision Processes},
author={Nathaniel S Keplinger and Baiting Luo and Yunuo Zhang and Kyle Hollins Wray and Aron Laszka and Abhishek Dubey and Ayan Mukhopadhyay},
booktitle={The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year={2025},
url={https://openreview.net/forum?id=YOXZuRy40U}
}
Installation#
To install NS-Gym, you can use pip:
pip install ns_gym
Alternatively, you can install the latest development version directly from the GitHub repository: .. code-block:
pip install git+https://github.com/scope-lab-vu/ns_gym
Decision Making Algorithm Support#
NS-Gym is designed to be compatible with existing reinforcement learning libraries such as Stable Baselines3. Additionally, NS-Gym provides baseline algorithms designed explicitly for non-stationary environments, as well as a leaderboard to compare the performance of different algorithms on various non-stationary tasks.
NS-Gym in Action#
Here are three examples of non-stationary environments created using NS-Gym. Each demonstrates a transition from an initial MDP \(\mathcal{MDP}_0\) to a modified MDP \(\mathcal{MDP}_1\) by changing environment parameters \(\theta_0 \rightsquigarrow \theta_1\). We show examples from the classic control suite (CartPole), stochastic gridworlds (FrozenLake), and the MuJoCo suite (Ant).
Note that this type of parameter shift is just one example of how an NS-MDP can be implemented. The policy controlling the CartPole and FrozenLake agents is the NS-Gym implementation of Monte Carlo Tree Search, while the Ant environment is controlled by a Stable-Baselines3 PPO policy.
Stationary MDP |
\(\large \theta_0 \rightsquigarrow \theta_1\) |
Non-Stationary MDP |
|---|---|---|
|
At timestep \(t\) gravity massively increases according to a user defined step function |
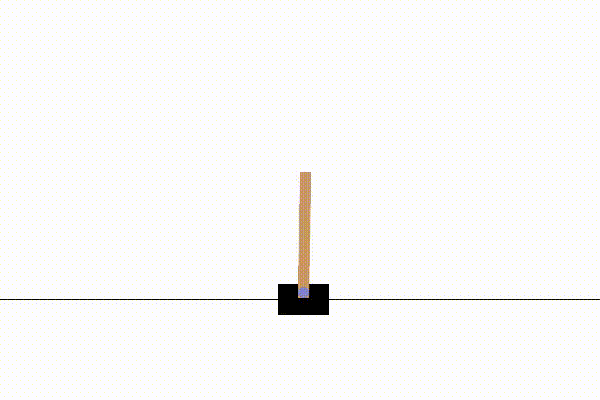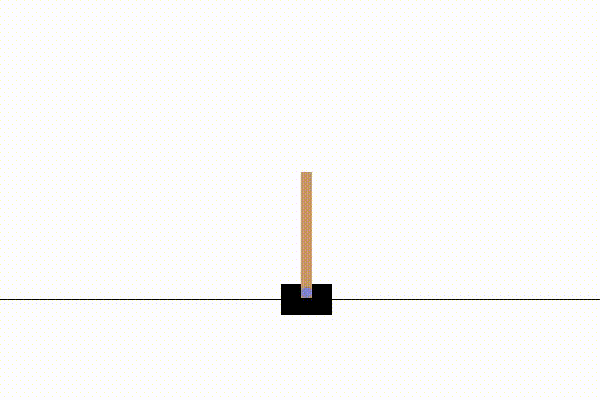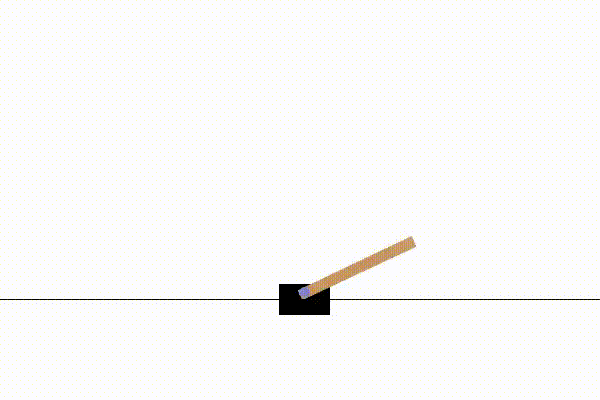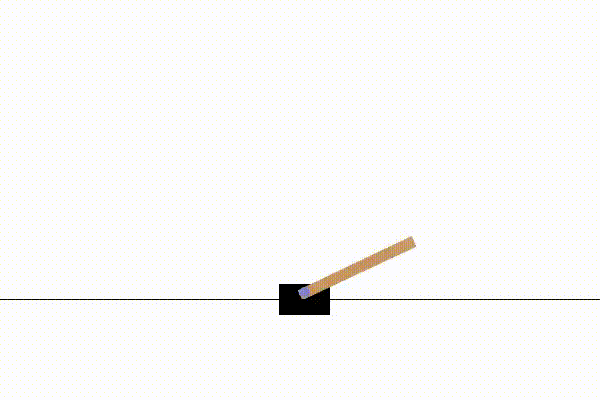
|

|
Probability of moving in the intended direction goes to 0 just before reaching the goal |

|

|
Magnitude of gravity gradually decreases at each timestep following a geometric progression |

|